最近在看书的时候突然纠结于Unicode相关字符编码,查了一些资料,并写了这篇文章,顺带做下笔记,希望能帮到一些人。文章如果有写的不妥的或者不正确的地方还请大家纠正。
Unicode 编码
Unicode是一个符号集,它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。解决传统的字符编码方案的局限。
历史上存在两个独立的尝试创立单一字符集的组织,即国际标准化组织(ISO)和非营利机构统一码联盟。前者开发的 ISO/IEC 10646 项目,后者开发的统一码项目。因此最初制定了不同的标准。他们不久便发现对方的存在,大家为着相同的目的而工作,最后他们合并双方的工作成果。统一码(Unicode)的编码方式与ISO 10646的通用字符集(Universal Character Set, 简称UCS)概念相对应。
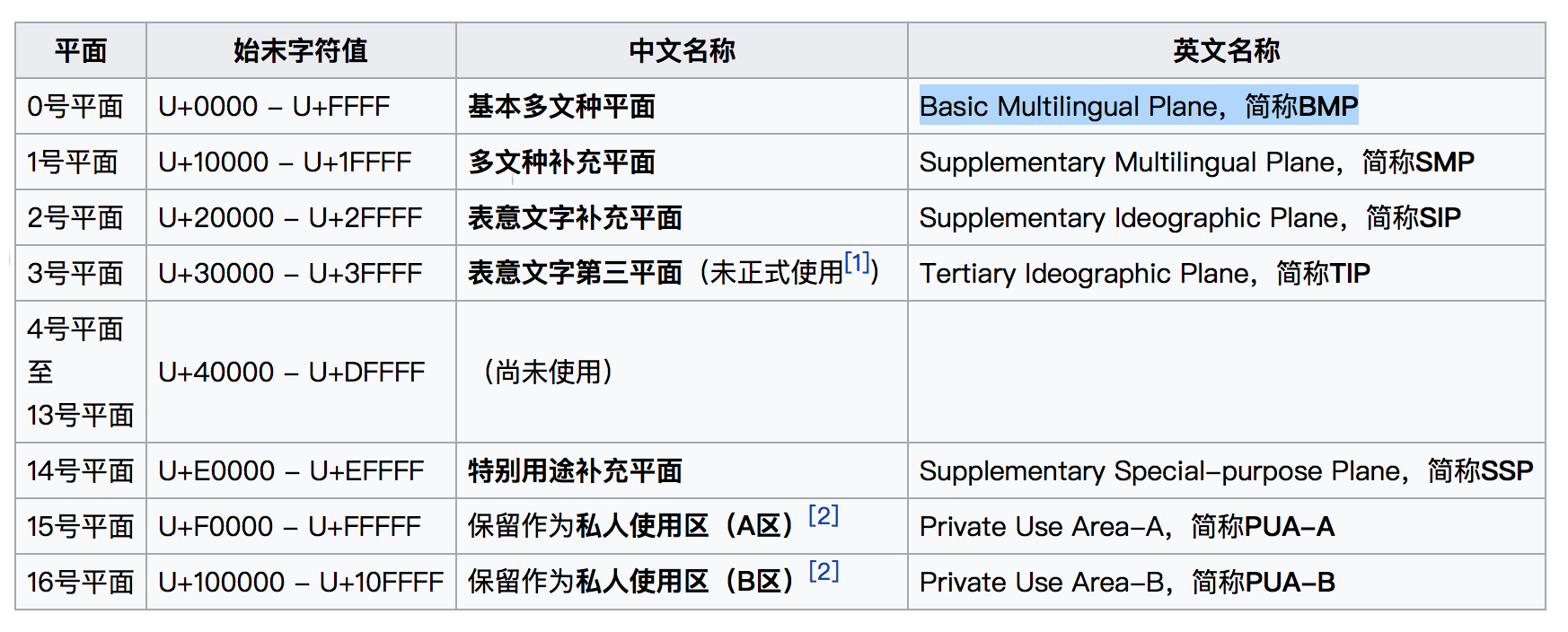
统一码的编码方式使用16位编码空间,也就是每个字符占用2个字节,最多可表示2^(16)个字符,基本满足各种语言的需求,且实际上16为编码空间并未完全使用,其中保留了大量空间作为未来备用。这里所说的16位编码空间即统一码的0号平面(也称“基本多文种平面”,Basic Multilingual Plane,简称BMP),目前统一码版本中另外定义了16个辅助平面,这样就需求21位编码空间,即 16+5 位,一共17个平面(不局限于),每个平面拥有2^(16)个代码点。如下表所示(摘自Wikipedia):
ASCII
ASCII(“阿斯柯”) 是国际上普遍采用的一种字符编码系统,由8位二进制进行编码,最高位恒为0,因此可以定义128个字符,其中包括10个十进制数字、52个英文大小写字母(A~Z, a~z)等。
UTF-8
UTF(Unicode Transformation Format, Unicode字符集转换格式),UTF-7、UTF-8、UTF-16、UTF-32、GB18030…只是Unicode的一种实现方式,即怎样将 Unicode 定义的数字转换成程序数据。
UTF-8 编码,以8位无符号整数为单位进行编码,是针对Unicode的可变长字符编码,UTF-8 是 ASCII 编码的父集,也就是说,UTF-8 与 ASCII 编码兼容,如:对于0x000000-0x00007F之间的字符,即前128个字符,UTF-8 编码与 ASCII 编码完全相同。这使得原来处理 ASCII 码字符的软件无须或只须做少部分修改,即可继续使用,UTF-8 编码应用广泛,基本所有互联网协议都支持 UTF-8 编码,是目前编码方式中优先采用的方式之一。
关于Unicode 与 UTF-8 编码之间的转换关系,如下表所示:
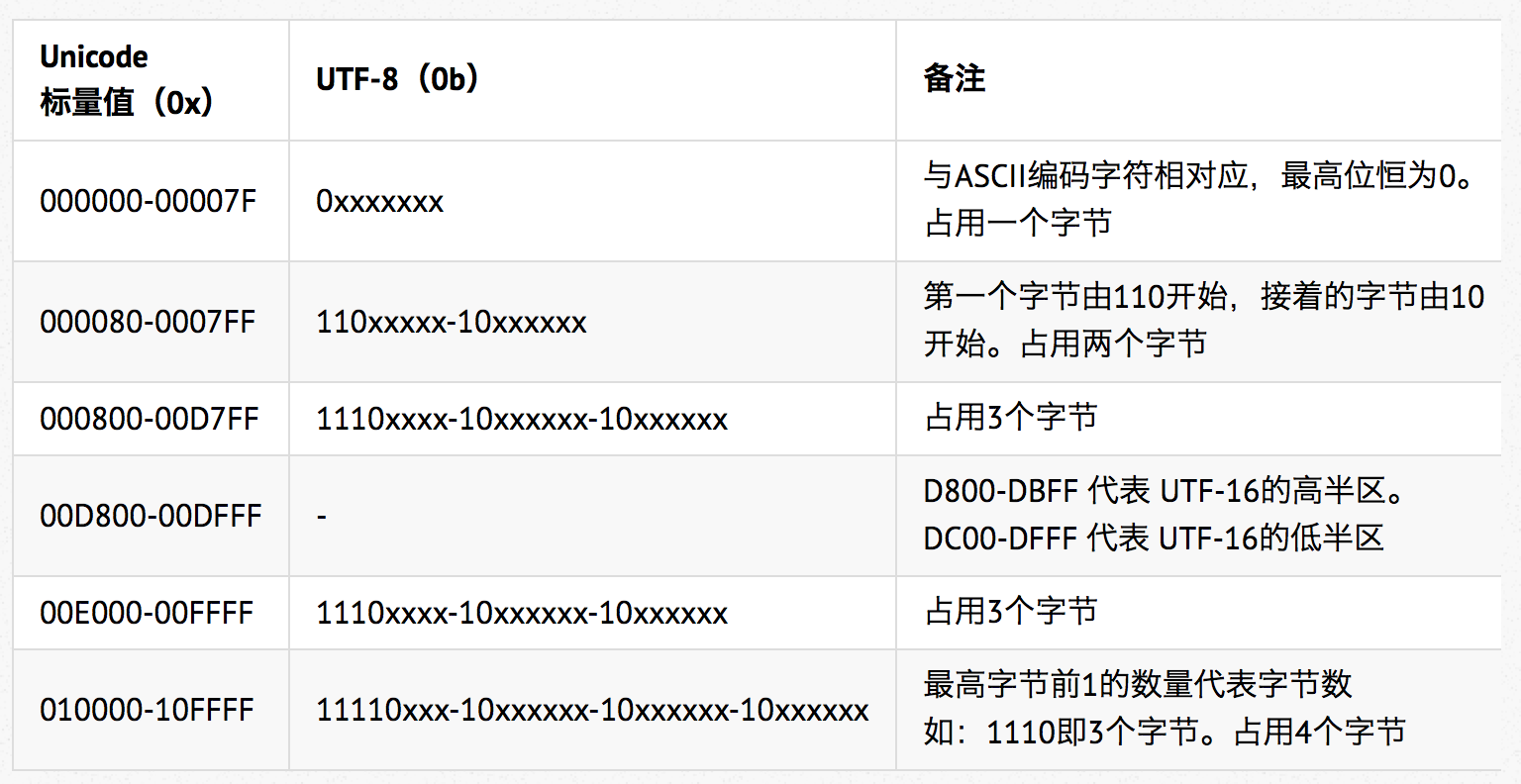
在基本多文种平面中约定00D800-00DFFF这范围用于UTF-16扩展标识辅助平面(即低位两个字节),在UTF-16 中会详细介绍。
举个例子,汉字“听”的 Unicode 编码是U+542C,转成UTF-8,步骤如下:
- 由上表可得出,“听”字的 Unicode 编码属于U+0800到U+D7FF区域,说明该字占用3个字节,按照1110xxxx-10xxxxxx-10xxxxxx进行填充。
- U+542C换算成二进制:0101-0100-0010-1100。
- 从低位向高位填充,代替x,11100101-10010000-10101100。
- 得出汉字“听”的UTF-8编码:0xE590AC。
从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。2003年11月 UTF-8 被 RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF。如果以上都能理解,那么下表就非常好理解了(摘自Wikipedia):
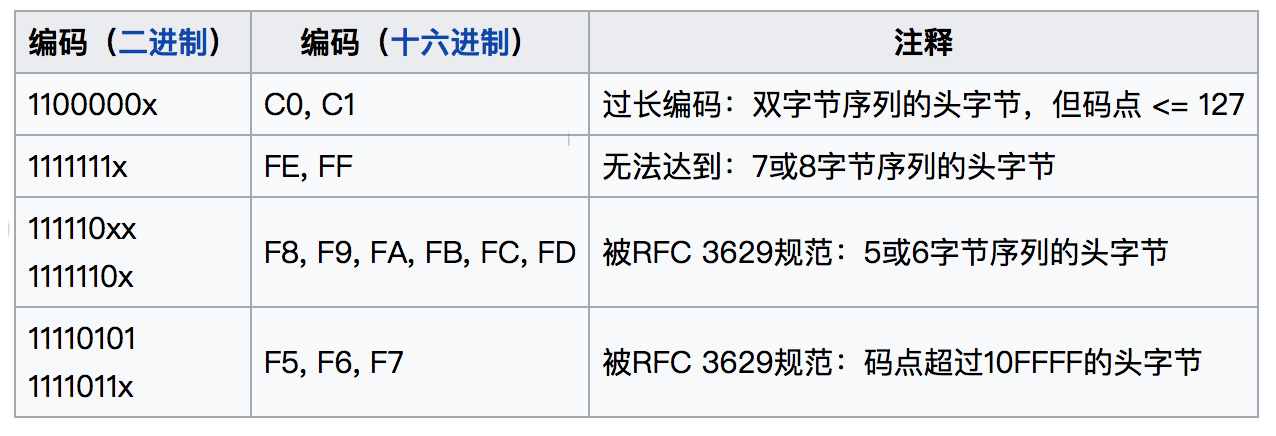
之前有较多的人在微博上私信我@tingxins,关于这表格,疑惑颇多,因此在此处进行补充并简单解释一下,希望能帮到读者。C0,C1非常好理解,不再详述。我们来看看F5-FF的头字节,为什么是非法的?我们可以以 U+10FFFF 为例,转UTF-8编码后,可以得出头字节二进制流为11110100,即F4,基于 RFC 3629 规范,因此可得出大于F4头字节的可以理解成非法的或者不可能出现的编码,就7或8字节序列的头字节而言,更是违反了早期UTF-8编码不可超过6字节序列的规范。(更新于 2017-2-18)
UTF-8 小结
- 在UTF-8文件的开首,以EF,BB,BF代表,以显示这个文本文件是以UTF-8编码。
- 字节0xFE和0xFF在UTF-8编码中从未用到,同时,UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一様的,没有字节序的问题,也因此它实际上并不需要BOM(字节顺序标记,Byte-Order Mark),但在UTF-16中用来标记存储方式(大端小端)。
- ASCII和UTF-8两种编码方式下是一样的,可以说UTF-8是ASCII编码的父集。
现在我们已经知道了UTF-8的含义,以及其编码原理,下面我们来探究一下 UTF-16 编码方式。
UTF-16
UTF-16 编码,以16位无符号整数为单位进行编码。上文中所提及到的“基本多文种平面”的编码空间中保留了一块区域(从U+D800到U+DFFF),该区域不映射Unicode字符,UTF-16就是利用保留下来的0xD800-0xDFFF编码空间来对U+10000到U+10FFFF(即辅助平面)进行字符映射的。
在 UTF-16 编码中,从U+0000至U+D7FF以及从U+E000至U+FFFF的编码空间的映射关系同 Unicode,相对应于ISO通用字符集中的USC-2。从U+10000到U+10FFFF的编码空间,UTF-16用一对16比特长的码元(即32bit,4Bytes)进行编码,熟称代理对(Surrogate Pair).
0xD800-0xDFFF编码空间分成两部分(即上述所说的代理对):
- UTF-16的高位代理:从U+D800至U+DBFF,也称前导代理(lead surrogates)。
- UTF-16的低位代理:从U+DC00至U+DFFF,也称后尾代理(trail surrogates)。
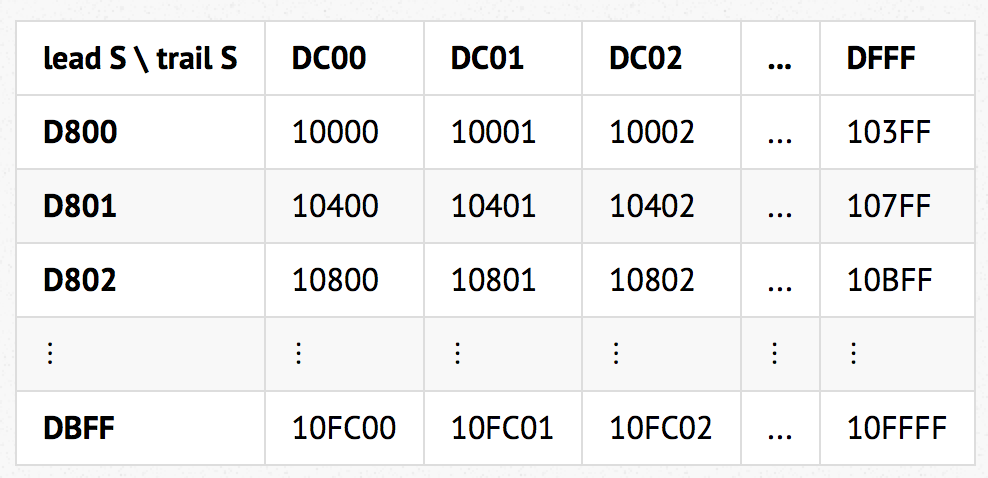
UTF-16 辅助平面编码方式比较巧妙,从U+10000到U+10FFFF,共计FFFFF个,即2^(20)个,至少需要20位来表示,我们再来看代理对,先看高半区,从U+D800到U+DBFF,共计3FF个,即2^(10)个,同理低半区也是2^(10)个,正好为2^(20)个代理对,这也是“基本多语言平面”中保留不对应于Unicode字符的2048个码位的原因。下面我们来看一张表:
举个例子,古意大利字母”𐌀”的Unicode编码为U+10300,转成UTF-16,步骤如下:
- 在0x10300的基础上先减去0x10000 –> 0x00300,转成二进制:0000-0000-0011-0000-0000。
- 得出高10位(0000-0000-00)和低10位(11-0000-0000)
- 添加0xD800到高10位(不足补0),得出UTF-16高位:0xD800 + 0x0000 –> 0xD800
- 添加0xDC00到低10位(不足补0),得出UTF-16低位:0xDC00 + 0x0300 –> 0xDF00
- 得出古意大利字母”𐌀”的UTF-16BE编码:U+D800DF00
关于Unicode 与 UTF-16 编码之间的转换关系,如下表所示:

由上表可看出,UTF-16无法兼容ASCII编码。
UTF-16 存储形式
想必读者现在有这样一个疑惑,UTF-16 是以16位无符号整数位单位进行编码,即每个字符占用两个字节,如:在Mac和Window上,对字节顺序的理解是不一样的,这时就出现了一个问题,同一字节流可能会被解释为不同内容,以字符“心“为例,该字符十六进制编码为U+5FC3,按两个字节进行拆分:5F和C3,在Mac上读取时是从低字节开始,那么在Mac OS会认为此U+5FC3编码为U+C35F,显示字符为”썟”,而在Windows上从高字节开始读取,则编码为U+5FC3的字符为“心”。为了解决该问题,字节顺序标记(Byte-Order Mark, BOM)诞生,字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前,反之同理。这两种字节序在计算机我们通常称大端和小端,下面我们来继续探究一下。
大端存储和小端存储
大端存储(Big Endian, 简称BE):一个字中的高位字节放在内存中这个字区域的低地址。小端存储(Little Endian, 简称LE):即一个字中的低位字节放在内存中这个字区域的低地址处。
还是以古意大利字母”𐌀”为例,我们刚已计算出其UTF-16编码为U+D800DF00,如果采用大端存储,编码存储的序列为D800 DF00,采用小端存储,则为00D8 00DF。这个两个存储模式的区别在于字中字节的存储顺序不同,而字的存储顺序是相同的。再看几个例子(摘自Wikipedia):
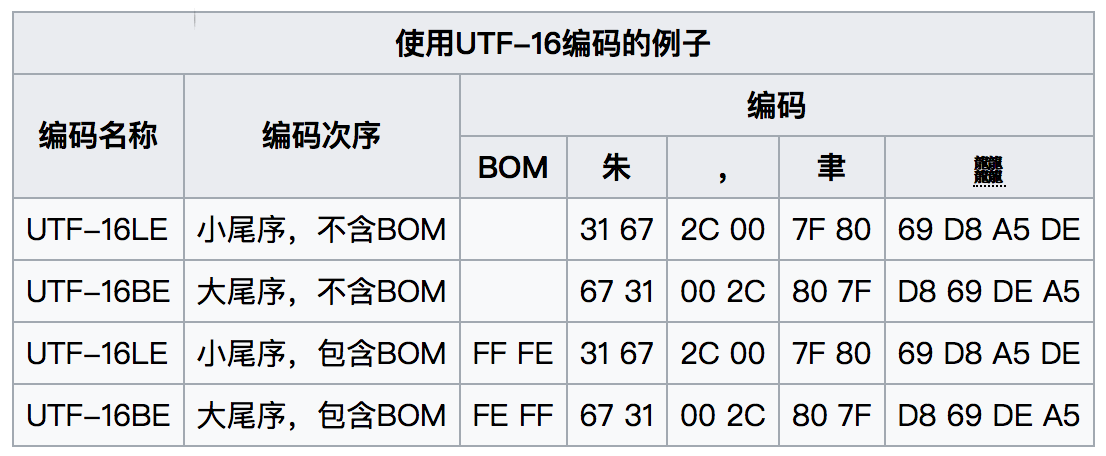
UTF-16 小结
- 在UTF-16文件的开首,以FEFF 或者 FFFE代表,以显示这个文本文件是以BE存储编码还是以LE存储编码。
- UTF-16编码可以说是UCS-2的父集,对于小于0x10000的Unicode码,UTF-16编码就等于UCS码,也可以说UTF-16编码就等于Unicode标量值。
- UTF-16 VS UTF-8,个人觉得这两种编码方式没有可比性,主要取决于字符本身主要集中在哪个平面,两者都是可变长度编码。
- UTF-16 VS UCS-21,如果这个字超过U+FFFF(如:U+10000至U+10FFFF),那么就无法用UCS-2的格式编码,UTF-16可看成是UCS-2的父集。
相关文章及链接
- 字符编码笔记:ASCII,Unicode和UTF-8
- Unicode Wikipedia
- UTF-8 Wikipedia
- 字节顺序标记 Wikipedia
- UTF-16 Wikipedia
- Unicode 字符平面映射
广告
欢迎关注微信公众号

-
UCS即ISO 10646的通用字符集(Universal Character Set, 简称UCS),UCS-2我们可以简单理解为UTF-16,同样使用16位的编码空间。 ↩